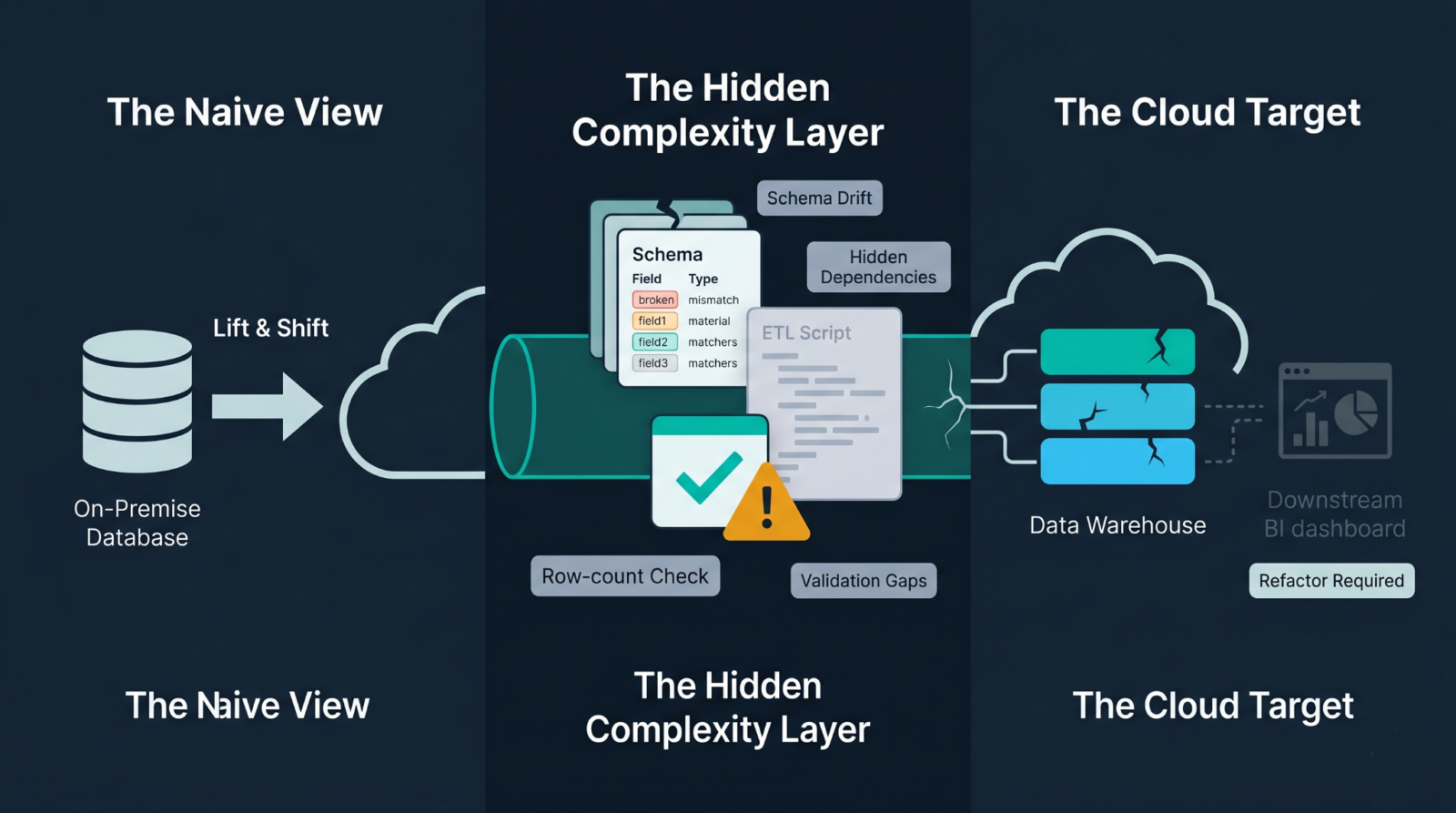
Migration of data into the cloud may seem straightforward. All you need is to choose an appropriate tool, map your schemas, and start migrating. In actual practice, it turns out to be one of the most underestimated processes in data engineering. Teams usually stumble upon unexpected problems due to undocumented sources, unstable transforms, and validation issues, which become apparent when the legacy system is taken down. If you are evaluating vendors or defining a migration brief, the data migration services is a useful reference for scoping the work.
Why Cloud Data Migration Projects Stall
Failure modes are known by now for enterprise data migration projects to the cloud. Teams approach data migration like copying rather than transforming data. If your source database is an on-premise Oracle data warehouse that has ten years of incrementality implemented using stored procedures, you don’t migrate your data. You transform it under tight time constraints.
Migration projects stall because of the following reasons:
- Undiscovered dependencies in transformation logic hiding inside your ETL scripts, scheduled jobs, or application layer code that were missed during discovery
- Schema drift with undocumented source database table changes that created a disparity between data dictionary and actual table content in production
- Validation gaps where counting rows is accepted as a validation mechanism while actual data corruption occurs because of incorrect type conversions or date formatting
Enterprise data migration to the cloud strategy must consider all these aspects upfront.
Choosing the Right Cloud Migration Strategy
The 6R method Rehost, Replatform, Refactor, Re-architect, Repurchase, and Retire has been considered a go-to reference when planning cloud migration for businesses ever since AWS introduced it. While it is still valid, the 6R model can use some additional practical advice, which is to consider individual workloads rather than projects.
A single migration project in the cloud could include the rehosting of raw ingests to S3, the replatforming of a Postgres database to Aurora, and a full refactoring of an on-premise data warehouse into Snowflake. Considering all three to be similar migration jobs is why most schedules fail to be met.
More specifically, while migrating a data warehouse, there is little choice but to refactor everything. Simply lifting the current infrastructure from the on-premise MPP architecture into a cloud-based data warehouse would not yield the desired result of better performance and lower cost. After all, the query structures, indexes, and other optimizations were designed for quite different hardware.
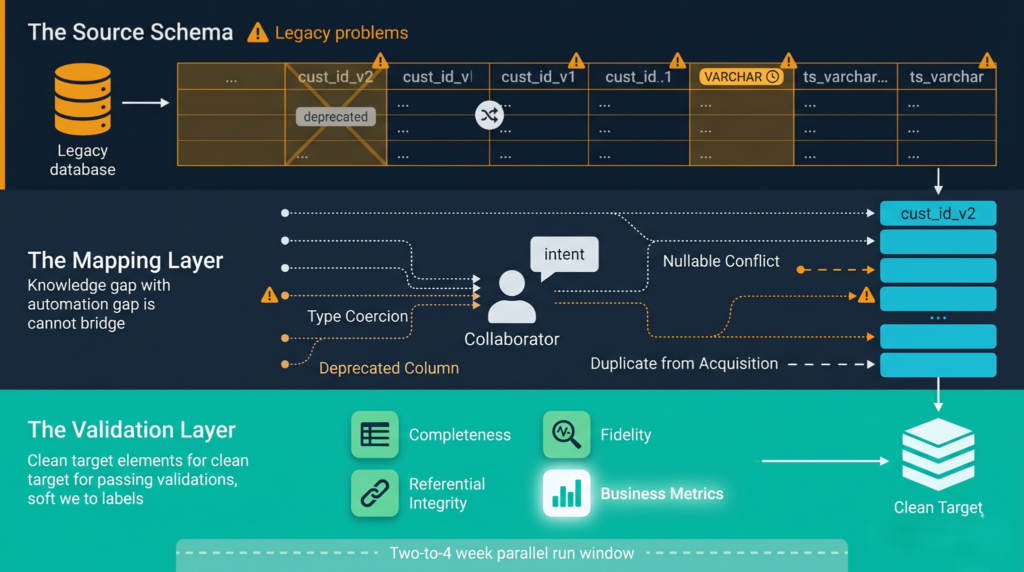
Schema Mapping Is Where Time Goes
Regardless of the volume involved, mapping is always the biggest time investment when migrating data from one cloud system to another. This is the case whether we are working with two tables or two thousand.
The reason lies in the fact that the existing system contains legacy baggage in its schema. The naming conventions of old columns that were updated long ago. Nullable fields that are required for all other systems. Columns storing timestamps in VARCHAR. All of it remains unknown until we map out the new schema and start comparing rows between the two databases.
Automation can help with the conversion. It will help convert the CREATE TABLE syntax, but not with the intent. An automation can easily translate a table creation query to a different system, but will never understand that the specific column became deprecated three years ago, or that there are two identical columns due to acquisition.
The only effective solution to this problem is engaging with the owners of the source data from the start. Schema mapping performed by engineers, but not based on the expertise of those who created or use the source system, will result in logically invalid schemas.
Building the Validation Layer
Cloud data migration validation is mostly an afterthought. People do some basic checks by running row counts and confirming that numbers match. However, this does not address the actual failure modes for downstream applications.
A comprehensive validation layer comprises four factors.
- Completeness: Row completeness at the partition or time range level and not just in total
- Fidelity: Values after the transformation process are intact with no trimming, rounding, or coercing to NULLs
- Referential Integrity: The referential relationship in existence in the source is maintained in the target
- Business Metrics: Key business metrics generated from the new dataset equate to those generated from the source data within a specific time period
The last point is the crucial element and it is the least automated one. This involves writing tests that know about the business rules and not only the data structures themselves. In regards to Snowflake migrations, doing a parallel period where both solutions ingest fresh data for two to four weeks prior to the source being shut down ensures there are adequate signals to detect parity issues.
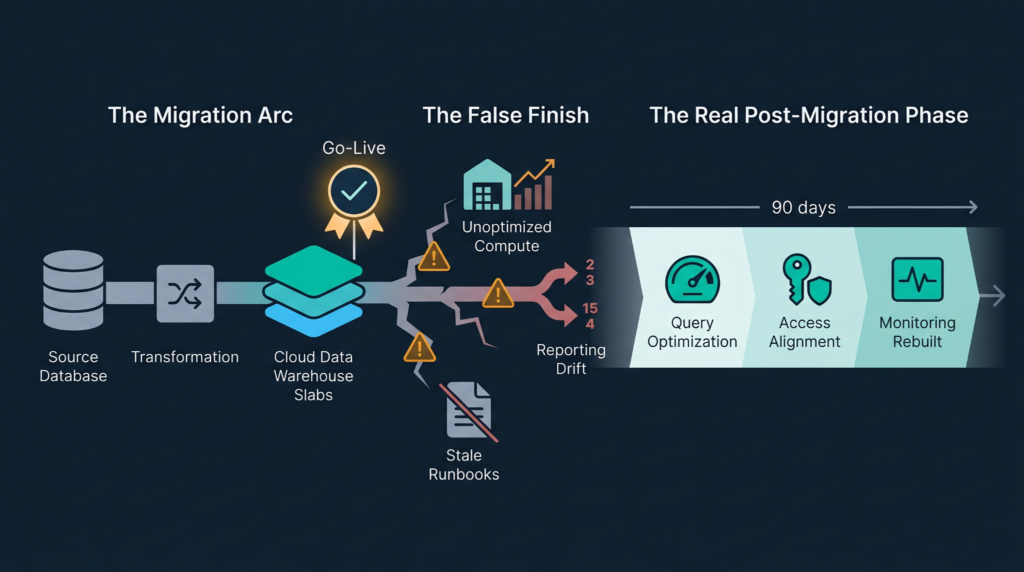
Post-Migration Is a Phase, Not a Finish Line
Data migration to the cloud is not over once the data has been migrated. This is where the actual work takes place during the months following go-live, which includes query optimization, cost tuning, alignment of permissions, and building back monitoring that may have relied on the previous infrastructure.
Companies that don’t take time for post-migration planning usually figure out three things in the first 90 days: they have higher than expected compute costs due to no optimization of warehouse size, their downstream reporting returns values that differ from those generated by the target system, and runbooks refer to the old system.
Getting this right requires treating cloud data migration as an end-to-end engagement rather than a one-time data transfer. Experienced data migration specialists work with teams across the full migration lifecycle, from initial assessment and schema mapping to pipeline validation and post-launch optimization, with a specific focus on Snowflake and modern cloud data warehouse environments